![[TR] HPE Morpheus Enterprise’da Monitoring Ayarları](https://kadirkozan.com/wp-content/uploads/2026/05/hpe_morpheus-ikona.jpg)
Bir bulut yönetim platformunun değeri yalnızca sanal makine, uygulama veya servis oluşturabilmesiyle ölçülmez. Kurumsal yapılarda asıl önemli konu oluşturulan bu iş yüklerinin gerçekten sağlıklı çalışıp çalışmadığını sürekli izleyebilmek, bir problem oluştuğunda bunu son kullanıcıdan önce fark edebilmek ve doğru ekibi doğru kanaldan hızlıca bilgilendirebilmektir.
HPE Morpheus Enterprise bu noktada yalnızca provisioning yani kaynak sağlama yapan bir platform değildir. Aynı zamanda sanal makinelerin, uygulamaların, servislerin, host’ların ve iş yüklerinin operasyonel durumunu takip edebilen güçlü bir izleme katmanı sunar.
Morpheus’un Monitoring modülü sayesinde sistemlerin erişilebilirliği ölçülebilir, olaylar incident olarak takip edilebilir. ServiceNow gibi ITSM sistemleriyle entegre çalışılabilir ve log kayıtları merkezi sistemlere yönlendirilebilir.
Bu makalemde HPE Morpheus Enterprise üzerindeki Administration > Settings > Monitoring ekranını detaylı olarak ele alacağız.
Morpheus’un izleme mantığını, otomatik check oluşturma yapısını, availability hesaplamalarını, ServiceNow entegrasyonunu, bildirim mekanizmasını ve log yönlendirme ayarlarını anlaşılır bir şekilde inceleyeceğiz.
Morpheus’ta İzleme Mantığı
HPE Morpheus Enterprise’ın izleme yaklaşımındaki en önemli avantajlardan biri izleme sürecinin provisioning ile doğal olarak entegre çalışmasıdır. Yani Morpheus üzerinden bir instance, app veya servis oluşturduğunuzda bu kaynağın izlenmesi için ayrıca tamamen manuel bir süreç yürütmeniz gerekmez.
HPE Morpheus Enterprise platformu uygun şekilde yapılandırıldığında yeni oluşturulan iş yükleri için otomatik olarak izleme kontrolleri meydana getirebilir. Böylece sistem yöneticilerinin her sanal sunucu için ayrı ayrı monitoring kaydı oluşturması gerekmez. Özellikle çok sayıda tenant, instance ve uygulamanın bulunduğu ortamlarda bu özellik ciddi operasyonel kolaylık sağlar.
Morpheus izleme mimarisi üç temel kavram üzerine kuruludur:
- Check: en küçük izleme birimidir. Bir sanal makinenin, servisin veya uygulama bileşeninin ayakta olup olmadığını kontrol eder. Örneğin bir web servisinin HTTP cevabı vermesi, bir veritabanı servisinin sorguya yanıt vermesi veya bir sunucunun erişilebilir olması check mantığıyla takip edilir.
- Group: birden fazla check’in mantıksal olarak bir araya getirildiği yapıdır. Örneğin aynı uygulamanın web katmanında çalışan üç farklı sunucu tek bir grup altında toplanabilir. Böylece her bir sunucu ayrı ayrı izlenirken, grubun genel sağlık durumu da takip edilebilir.
- App: uygulamanın uçtan uca sağlık durumunu temsil eden en üst seviyedeki yapıdır. Bir uygulama birden fazla grup ve check içerebilir. Bu sayede yalnızca tekil sunucular değil, tüm uygulama mimarisi izleme kapsamına alınabilir.
Bu hiyerarşik yapı özellikle yedekli sistemlerde çok değerlidir. Örneğin üç sunuculu ve load balancer arkasında çalışan bir web katmanında tek bir sunucunun kapanması uygulamanın tamamen erişilemez olduğu anlamına gelmeyebilir. HPE Morpheus bu tür yapılarda check ve group mantığını kullanarak uygulamanın gerçek erişilebilirlik durumunu daha doğru değerlendirebilir.
Monitoring Ayarlarına Nereden Erişilir?
HPE Morpheus Enterprise’da global izleme ayarlarına ulaşmak için yönetim arayüzünde şu yol izlenir:
Administration > Settings > Monitoring
Bu ekran, Morpheus platformundaki genel monitoring davranışlarını belirlemek için kullanılır. Burada yapılan ayarlar, yeni oluşturulan kontroller için varsayılan değerleri belirler. Yani her kontrolü tek tek oluştururken aynı değerleri tekrar girmek yerine, temel davranışı bu ekrandan merkezi olarak tanımlayabilirsiniz.
Monitoring sekmesi genel olarak üç ana bölümden oluşur;
| Bölüm | Açıklama |
|---|---|
| Morpheus | Yerleşik izleme motorunun temel davranışlarını belirler. |
| ServiceNow | Morpheus incident kayıtlarının ServiceNow ile entegre çalışmasını sağlar. |
| Logging Settings | Log toplama, log seviyesi ve syslog yönlendirme ayarlarını içerir. |
Bu bölümler birlikte değerlendirildiğinde Morpheus’un yalnızca sistemleri izleyen değil olayları yöneten ve logları merkezi sistemlere aktarabilen bir operasyon platformu haline geldiği görülür.
1. Morpheus Monitoring Settings
Monitoring ekranının ilk bölümünde Morpheus’un yerleşik izleme motoruna ait temel ayarlar bulunur. Bu ayarlar, yeni oluşturulan kaynakların nasıl izleneceğini, availability değerlerinin nasıl hesaplanacağını ve check’lerin hangi sıklıkta çalışacağını belirler.
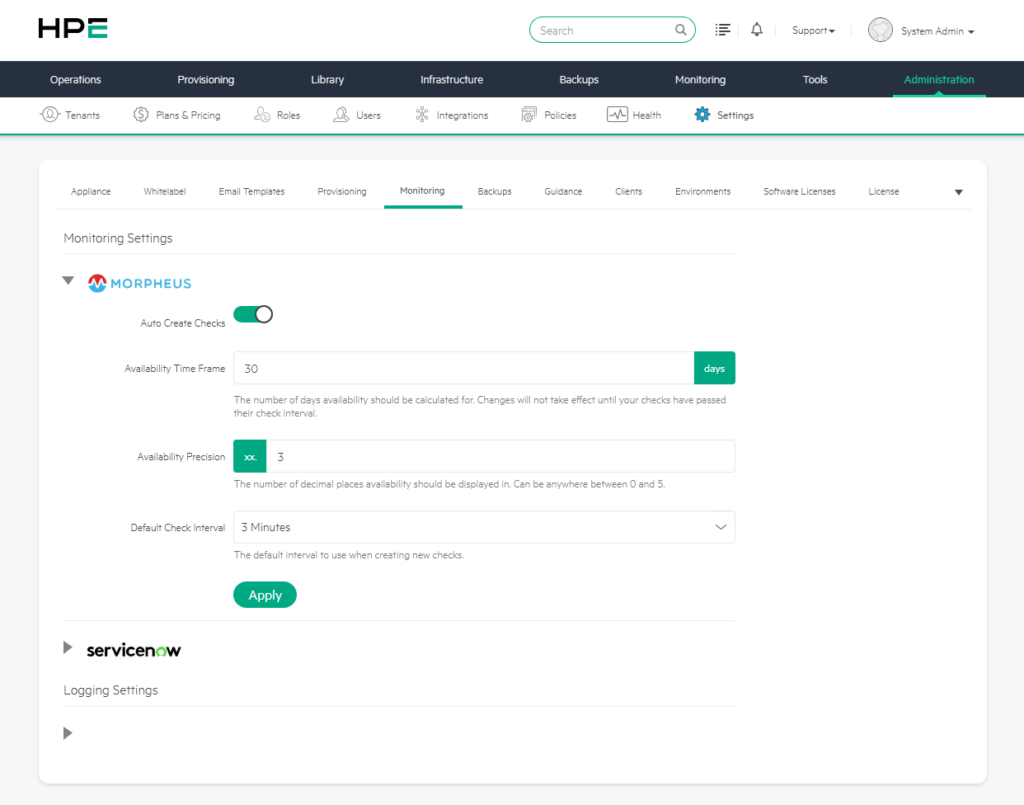
Bu bölümde yer alan temel ayarlar şunlardır:
- Auto Create Checks,
- Availability Time Frame,
- Availability Precision,
- Default Check Interval,
a) Auto Create Checks
Auto Create Checks Morpheus üzerinden oluşturulan instance ve app kaynakları için izleme kontrollerinin otomatik olarak oluşturulup oluşturulmayacağını belirleyen ayardır.
Bu seçenek aktif hale getirildiğinde Morpheus, yeni oluşturulan kaynaklar için arka planda otomatik check oluşturabilir. Örneğin bir tenant kullanıcısı self-service portal üzerinden yeni bir sanal sunucu oluşturduğunda, bu sunucu için temel monitoring kontrolü otomatik olarak devreye alınabilir.
Bu özellik özellikle büyük ortamlarda oldukça faydalıdır. Çünkü sistem yöneticilerinin her yeni sanal sunucu için ayrıca izleme tanımı yapması gerekmez. Böylece “sunucu oluşturuldu ama monitoring’e eklenmedi” gibi operasyonel hataların önüne geçilir.
Auto Create Checks özelliği kapatılırsa Morpheus yeni kaynaklar için otomatik kontrol oluşturmaz. Bu durumda hangi sistemlerin izleneceği manuel olarak belirlenmelidir. Bu yaklaşım bazı özel yapılarda tercih edilebilir. Örneğin yalnızca kritik sistemlerin izlenmesi isteniyorsa veya izleme yükü bilinçli olarak sınırlandırılmak isteniyorsa otomatik check oluşturma kapatılabilir.
Ancak çoğu kurumsal ortamda bu ayarın açık bırakılması önerilir. Çünkü izleme, provisioning sürecinin doğal bir parçası haline geldiğinde sistem yönetimi çok daha kontrollü yürütülür.
b) Availability Time Frame
Availability Time Frame erişilebilirlik oranının kaç günlük veri üzerinden hesaplanacağını belirleyen ayardır. Ekranda bu değerin 30 gün olarak tanımlandığı görülmektedir.
Bu ayar Morpheus’un availability yani kullanılabilirlik yüzdesini hesaplarken hangi zaman aralığını dikkate alacağını belirler. Örneğin değer 30 gün olarak yapılandırılmışsa, bir instance veya uygulama için görüntülenen erişilebilirlik oranı son 30 günlük check sonuçlarına göre hesaplanır.
Bu değer özellikle SLA takibi açısından önemlidir. Kurumlar veya hizmet sağlayıcılar genellikle aylık servis sürekliliği raporları oluşturur. Böyle bir yapıda 30 günlük availability time frame değeri mantıklı bir tercihtir.
Örneğin bir hizmet için aylık %99,9 uptime hedefleniyorsa Morpheus bu hedefin gerçekleşip gerçekleşmediğini son 30 günlük izleme verisine göre gösterebilir.
Burada dikkat edilmesi gereken önemli bir nokta vardır. Availability Time Frame değiştirildiğinde, bu değişiklik hemen tüm sonuçlara yansımayabilir. Kontroller kendi check interval sürelerine göre çalışmaya devam eder ve yeni hesaplama bir sonraki izleme döngülerinden sonra anlamlı şekilde oluşur.
Kısa süreli analizler için daha düşük değerler uzun dönemli trend analizi için ise daha yüksek değerler tercih edilebilir. Ancak en doğru yaklaşım, bu değeri kurumun SLA raporlama periyoduyla uyumlu seçmektir.
c) Availability Precision
Availability Precision erişilebilirlik oranının kaç ondalık basamakla gösterileceğini belirler. Ekranda bu değerin 3 olarak ayarlandığı görülmektedir.
Bu ayar ilk bakışta küçük bir detay gibi görünebilir. Ancak özellikle yüksek erişilebilirlik hedefi olan ortamlarda oldukça önemlidir. Çünkü %99,9 ile %99,999 arasında operasyonel olarak büyük fark vardır.
Örneğin precision değeri 3 olduğunda availability oranı şu şekilde gösterilebilir:
99.987%
Eğer precision değeri 1 olsaydı aynı oran daha yuvarlanmış şekilde görünebilirdi:
99.9%
Bu durum bazı raporlarda yeterli olabilirken, yüksek SLA hedefleri olan ortamlarda ayrıntının kaybolmasına neden olabilir. Özellikle müşteri bazlı hizmet veren yapılarda availability değerinin 2 veya 3 ondalık basamakla gösterilmesi daha sağlıklı olur.
Morpheus üzerinde bu değer genellikle 0 ile 5 arasında yapılandırılabilir. Daha sade yönetim ekranları için düşük hassasiyet, daha detaylı SLA raporları için ise yüksek hassasiyet tercih edilebilir.
d) Default Check Interval
Default Check Interval yeni oluşturulan izleme kontrollerinin varsayılan olarak hangi sıklıkla çalışacağını belirler. Ekranda bu değerin 5 Minutes olarak seçildiği görülmektedir.
Bu ayar Morpheus’un oluşturduğu yeni check’lerin ne kadar aralıklarla çalışacağını belirler. Örneğin 5 dakika seçiliyse, ilgili sistem veya servis her 5 dakikada bir kontrol edilir.
Kontrol aralığı belirlenirken iki unsur dengelenmelidir.
- Birincisi, sorunun hızlı fark edilmesidir. Check interval ne kadar kısa olursa, bir problem o kadar hızlı tespit edilir. Kritik servislerde bu oldukça önemlidir.
- İkincisi ise kaynak tüketimidir. Çok fazla sistemin çok kısa aralıklarla kontrol edilmesi, hem Morpheus appliance üzerinde hem de izlenen sistemlerde ek yük oluşturabilir.
Bu nedenle 5 dakikalık varsayılan değer birçok üretim ortamı için dengeli bir seçimdir. Kritik veritabanları, ödeme sistemleri veya müşteri erişimli servislerde bu süre 1 dakikaya kadar düşürülebilir. Daha az kritik test sistemleri veya düşük öncelikli servislerde ise 10 veya 15 dakikalık aralıklar tercih edilebilir.
Buradaki değer yalnızca varsayılan değerdir. Her check kendi detay ekranında ayrıca özelleştirilebilir. Yani global olarak 5 dakika belirlenmiş olsa bile, kritik bir servis için ayrı bir check interval tanımlamak mümkündür.
Check Davranışını Anlamak
Monitoring ayarlarını doğru yorumlayabilmek için Morpheus’un check mekanizmasının arka planda nasıl çalıştığını anlamak gerekir.
Morpheus check yapısı izlenen kaynağın türüne göre uygun kontrol yöntemini kullanabilir. Örneğin bir web servisi için HTTP tabanlı bir kontrol, bir veritabanı için sorgu tabanlı bir kontrol veya farklı bir servis için port ya da servis erişilebilirlik kontrolü kullanılabilir.
Morpheus’un izleme davranışında yanlış alarmları azaltmaya yönelik bazı önemli mekanizmalar bulunur.
Bir check başarısız olduğunda Morpheus bunu hemen kalıcı bir problem olarak değerlendirmez. Öncelikle kısa bir süre sonra yeniden kontrol eder. Bu yaklaşım anlık ağ dalgalanmaları veya geçici cevap gecikmeleri nedeniyle gereksiz alarm oluşmasını engeller.
Eğer tekrar denemede de başarısızlık devam ederse ilgili check hata durumuna geçer ve bu durum incident oluşmasına neden olabilir.
Bir check tekrar başarılı hale geldiğinde ise sistem doğrudan tamamen sağlıklı kabul edilmeyebilir. Belirli sayıda başarılı kontrol tamamlanana kadar uyarı durumunda kalabilir. Bu davranış özellikle kısa süreli düzelip tekrar bozulan sistemlerde daha güvenilir bir izleme sonucu sağlar.
Her check için bir Max Severity değeri bulunur. Bu değer ilgili kontrol başarısız olduğunda oluşturulabilecek incident kaydının ulaşabileceği en yüksek önem seviyesini belirler. Varsayılan olarak kritik seviyeye kadar çıkabilir.
Bu yapı sayesinde her kontrol aynı önem seviyesinde değerlendirilmek zorunda değildir. Örneğin test ortamındaki bir servis hata verdiğinde warning seviyesinde kalabilirken, üretim ortamındaki kritik bir servis critical seviyesinde incident oluşturabilir.
Group Mantığı ve Yedeklilik
Morpheus’ta group yapısı yedekli sistemleri doğru modellemek için oldukça kullanışlıdır.
Örneğin bir uygulamanın üç web sunucusu olduğunu düşünelim. Bu üç sunucudan biri erişilemez hale geldiğinde uygulama halen çalışıyor olabilir. Eğer her sunucu bağımsız kritik alarm üretiyorsa, operasyon ekipleri gereksiz bildirimlerle yorulabilir.
Group yapısı sayesinde “bu gruptaki en az iki kontrol başarılıysa grup sağlıklı kabul edilsin” gibi bir mantık kurulabilir. Böylece tek bir node arızası hemen büyük bir kriz gibi algılanmaz. Ancak birden fazla node devre dışı kalırsa uygulamanın gerçek erişilebilirliği etkilenmeye başladığı için incident seviyesi yükseltilebilir.
Bu yaklaşım alarm yorgunluğunu azaltır ve ekiplerin gerçekten müdahale edilmesi gereken olaylara odaklanmasını sağlar.
2. ServiceNow Entegrasyonu
Monitoring ekranındaki ikinci önemli bölüm ServiceNow entegrasyonudur. ServiceNow birçok kurumda IT servis yönetimi, incident takibi, problem yönetimi ve değişiklik yönetimi için kullanılan merkezi platformlardan biridir.
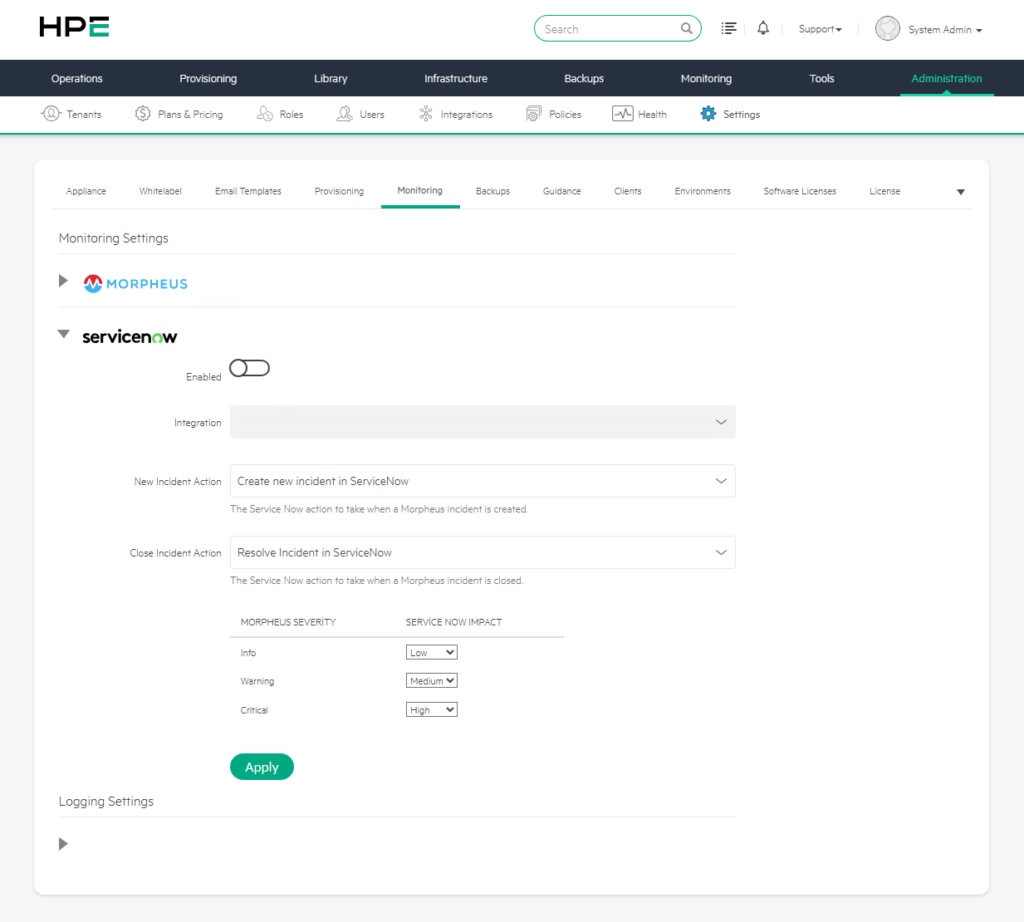
Morpheus üzerinde oluşan izleme olaylarının ServiceNow’a aktarılması operasyonel süreçlerin daha kurumsal ve takip edilebilir hale gelmesini sağlar. Bu entegrasyon sayesinde Morpheus’ta oluşan bir incident otomatik olarak ServiceNow tarafında kayıt haline getirilebilir.
ServiceNow bölümünde yer alan temel ayarlar şunlardır:
- Enabled
- Integration
- New Incident Action
- Close Incident Action
- Severity / Impact Mapping
ServiceNow Entegrasyonu İçin Ön Koşul
Monitoring ekranındaki ServiceNow bölümünü kullanabilmek için öncelikle Morpheus üzerinde ServiceNow entegrasyonunun tanımlanmış olması gerekir.
Bu işlem genellikle şu bölümden yapılır:
Administration > Integrations
Burada ServiceNow bağlantısı oluşturulur. Bağlantı için ServiceNow instance adresi, kullanıcı bilgileri, API erişim yetkileri ve gerekli kimlik doğrulama bilgileri tanımlanır.
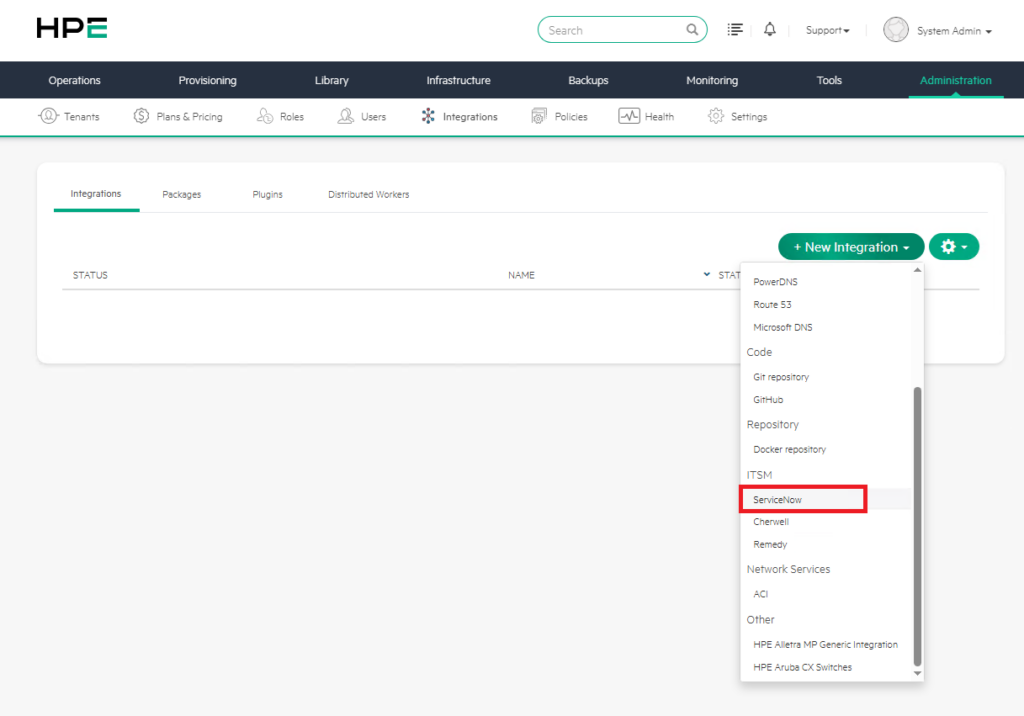
Monitoring ekranındaki ServiceNow bölümü ise var olan entegrasyonu monitoring olaylarıyla ilişkilendirir. Yani ServiceNow bağlantısının kendisi bu ekranda oluşturulmaz; daha önce tanımlanmış entegrasyon burada seçilerek olay yönetimi sürecine dahil edilir.
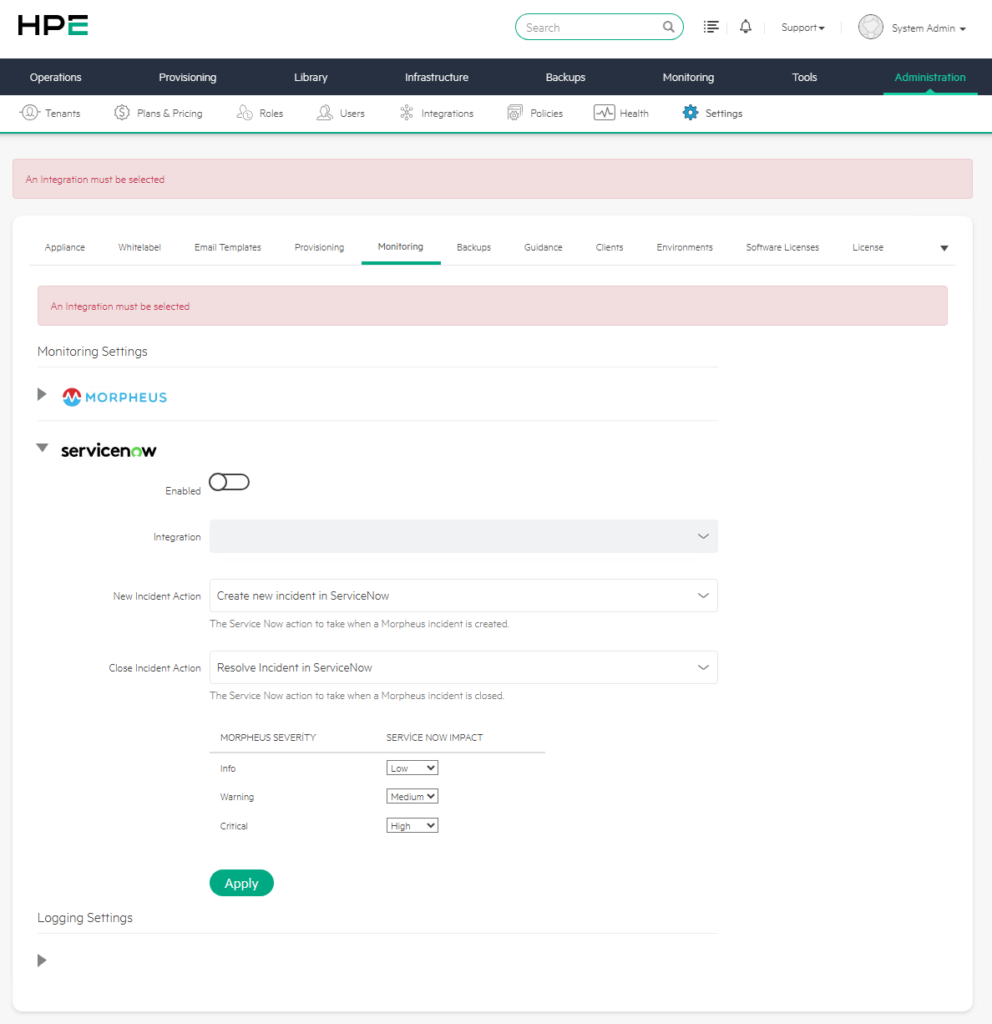
a) Enabled
Enabled, ServiceNow izleme entegrasyonunu aktif veya pasif hale getiren ana seçenektir.
Bu seçenek aktif olduğunda Morpheus üzerinde oluşan monitoring incident kayıtları yapılandırmaya bağlı olarak ServiceNow tarafında karşılık bulabilir. Eğer bu seçenek kapalıysa Morpheus kendi içinde incident oluşturmaya devam edebilir ancak ServiceNow tarafına otomatik kayıt göndermez.
b) Integration
Integration, kullanılacak ServiceNow entegrasyonunun seçildiği alandır.
Bu listede daha önce Administration > Integrations bölümünde tanımlanmış ServiceNow bağlantıları görünür. Eğer bu alan boş veya pasif görünüyorsa öncelikle ServiceNow entegrasyonunun oluşturulması gerekir.
Kurumsal yapılarda birden fazla ServiceNow ortamı bulunabilir. Örneğin test, staging ve production ServiceNow instance’ları ayrı olabilir. Bu nedenle doğru entegrasyonun seçilmesi önemlidir.
c) New Incident Action
New Incident Action Morpheus üzerinde yeni bir incident oluştuğunda ServiceNow tarafında hangi işlemin yapılacağını belirler.
Ekranda bu alanın şu şekilde ayarlı olduğu görülmektedir:
Create new incident in ServiceNow
Bu seçenek aktif olduğunda, Morpheus’ta oluşan yeni bir monitoring olayı ServiceNow üzerinde yeni bir incident kaydı olarak açılır. Örneğin kritik bir sanal sunucu erişilemez hale geldiğinde Morpheus bu durumu algılar, incident oluşturur ve ServiceNow tarafında ilgili ekiplerin takip edebileceği bir kayıt meydana getirir. Bu yaklaşım özellikle ITIL süreçleri uygulayan kurumlarda oldukça değerlidir. Çünkü olayın kayıt altına alınması, önceliklendirilmesi, atanması, takibi ve kapanışı merkezi ITSM süreci üzerinden yönetilebilir.
d) Close Incident Action
Close Incident Action Morpheus üzerindeki incident kapandığında ServiceNow tarafında hangi işlemin yapılacağını belirler.
Ekranda bu alanın şu şekilde ayarlandığı görülmektedir:
Resolve Incident in ServiceNow
Bu seçenek sayesinde Morpheus üzerinde problem çözüldüğünde, ServiceNow tarafındaki incident da otomatik olarak çözümlenebilir. Örneğin bir servis kısa süreli erişilemez hale geldi ve ServiceNow’da incident açıldı. Servis tekrar sağlıklı hale geldiğinde Morpheus olayı kapatır. Bu durumda ServiceNow kaydı da otomatik olarak “resolved” durumuna alınabilir. Bu yapı manuel iş yükünü azaltır ve gereksiz açık incident kayıtlarının birikmesini engeller. Ancak bazı kurumlarda incident kapanışları manuel onay veya ek kontrol gerektirebilir. Böyle ortamlarda otomatik resolve davranışı kurum prosedürlerine göre dikkatlice değerlendirilmelidir.
e) Morpheus Severity ve ServiceNow Impact Eşleştirmesi
ServiceNow bölümünün en önemli alanlarından biri severity ve impact eşleştirmesidir. Morpheus üzerindeki olay önem dereceleri ServiceNow tarafındaki impact seviyeleriyle eşleştirilir.
Ekranda görülen varsayılan yapı şu şekildedir:
| Morpheus Severity | ServiceNow Impact |
|---|---|
| Info | Low |
| Warning | Medium |
| Critical | High |
Bu eşleştirme sayesinde Morpheus’ta kritik olarak algılanan bir olay ServiceNow tarafında yüksek etki seviyesine sahip incident olarak açılabilir.
Bu ayarın doğru yapılandırılması oldukça önemlidir. Çünkü yanlış eşleştirme operasyonel önceliklendirmeyi bozabilir.
Örneğin Morpheus’ta critical olan bir olay ServiceNow tarafında low impact ile açılırsa destek ekibi olayı düşük öncelikli değerlendirebilir ve müdahale gecikebilir.
Varsayılan Info → Low, Warning → Medium, Critical → High eşleştirmesi çoğu ortam için mantıklı bir başlangıçtır. Ancak kurumun ITSM sürecine SLA yapısına ve destek ekiplerinin önceliklendirme modeline göre bu değerlerin gözden geçirilmesi önerilir.
3. Logging Settings
Monitoring ekranının alt kısmında Logging Settings bölümü yer alır. Bu bölüm Morpheus üzerindeki log toplama ve log yönlendirme davranışlarını yönetmek için kullanılır.
Monitoring kontrolleri bir sistemin sağlıklı olup olmadığını gösterir. Log kayıtları ise bir problemin neden meydana geldiğini anlamaya yardımcı olur. Bu nedenle izleme ve loglama birlikte düşünülmelidir.
Morpheus’un loglama yapısı yönetilen sistemlerden gelen günlük kayıtlarının merkezi olarak görüntülenmesine ve analiz edilmesine imkân sağlar. Bu loglar instance, app ve host detaylarında veya genel Monitoring > Logs bölümünde incelenebilir.
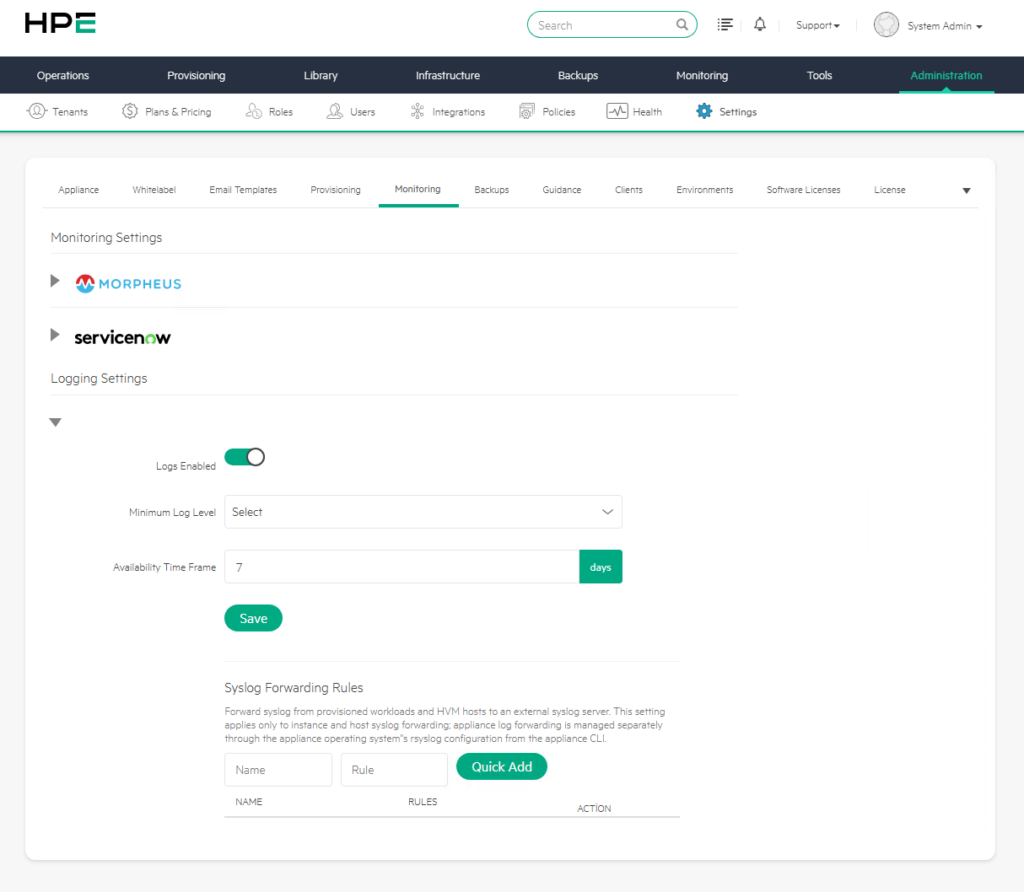
a) Logs Enabled
Logs Enabled log toplama özelliğini aktif veya pasif hale getiren seçenektir.
Bu ayar açık olduğunda Morpheus, yönetilen iş yüklerinden ve uygun kaynaklardan gelen log kayıtlarını toplayabilir. Ekranda bu seçeneğin aktif olduğu görülmektedir.
Kurumsal yapılarda loglama genellikle açık bırakılmalıdır. Çünkü bir olay yaşandığında yalnızca monitoring alarmı yeterli değildir. Olayın neden oluştuğunu anlamak için log kayıtlarına ihtiyaç duyulur.
Örneğin bir web servisi erişilemez hale geldiğinde monitoring bunu tespit eder. Ancak problemin uygulama hatasından mı, disk doluluğundan mı, servis çökmesinden mi yoksa bağlantı probleminden mi kaynaklandığını anlamak için log kayıtları incelenmelidir.
b) Minimum Log Level
Minimum Log Level hangi seviyeden itibaren log kayıtlarının toplanacağını belirler.
Ekranda bu alanın henüz seçilmemiş ve Select olarak göründüğü anlaşılmaktadır. Bu değerin doğru seçilmesi, log kalitesi ve depolama kullanımı açısından önemlidir.
Genel olarak log seviyeleri şu mantıkla değerlendirilir:
| Log Seviyesi | Açıklama |
|---|---|
| Debug | Çok detaylı teknik kayıtlar içerir. Sorun giderme sırasında kullanılır. |
| Info | Genel operasyonel bilgi kayıtlarını içerir. |
| Warning | Dikkat edilmesi gereken ancak sistemi tamamen durdurmayan olayları gösterir. |
| Error | Hata durumlarını gösterir. |
| Critical | Kritik hata veya servis kesintisi durumlarını ifade eder. |
Minimum log seviyesi düşük tutulursa daha fazla detay elde edilir. Ancak bu durum log hacmini artırır ve depolama kullanımını yükseltir.
Minimum log seviyesi yüksek tutulursa gereksiz kayıtlar azalır, ancak problem anında ihtiyaç duyulabilecek bazı ayrıntılar kaybedilebilir.
Production ortamlarında genellikle Info, Warning veya Error seviyeleri tercih edilir. Debug seviyesi ise sürekli açık bırakılmamalı, yalnızca belirli bir sorunu analiz etmek için geçici olarak kullanılmalıdır.
c) Logging Availability Time Frame
Logging Settings altında yer alan Availability Time Frame ekran görüntüsünde 7 days olarak görülmektedir.
Bu değer logların ne kadar süreyle tutulacağını veya log verisinin hangi zaman aralığında değerlendirileceğini belirleyen önemli bir ayardır. Kullanıcının belirttiği yapıya göre Morpheus logları ElasticSearch üzerinde saklar ve bu süre, log kayıtlarının ne kadar geriye dönük görüntülenebileceğini etkiler.
7 günlük süre kısa vadeli operasyonel analizler için yeterli olabilir. Örneğin son bir haftadaki hataları, servis kesintilerini veya tekrar eden problemleri incelemek için bu değer kullanılabilir.
Ancak regülasyon, güvenlik denetimi veya uzun süreli analiz gerektiren yapılarda bu süre yetersiz kalabilir. Böyle durumlarda logların merkezi bir SIEM, syslog veya log analiz platformuna yönlendirilmesi daha doğru olur.
Log retention süresi belirlenirken şu faktörler dikkate alınmalıdır:
- Ortamdaki sistem sayısı
- Üretilen günlük log hacmi
- ElasticSearch depolama kapasitesi
- Regülasyon ve denetim gereksinimleri
- Olay inceleme süreçlerinde ihtiyaç duyulan geçmiş veri süresi
d) Syslog Forwarding Rules
Logging Settings bölümünün altında Syslog Forwarding Rules alanı bulunur. Bu alan Morpheus tarafından toplanan veya yönetilen bazı syslog kayıtlarının harici syslog sunucularına yönlendirilmesini sağlar.
Bu özellik özellikle kurumsal güvenlik ve operasyon ekipleri için önemlidir. Çünkü birçok kurumda loglar merkezi bir SIEM, log management veya security monitoring platformuna aktarılır.
Morpheus üzerindeki Syslog Forwarding Rules alanı sayesinde loglar yalnızca Morpheus içinde kalmaz; kurumun merkezi log altyapısına da iletilebilir.
Bu bölümde genellikle şu alanlar bulunur:
| Alan | Açıklama |
|---|---|
| Name | Oluşturulacak syslog yönlendirme kuralının adıdır. |
| Rule | Yönlendirme kuralı veya hedef syslog bilgisi girilir. |
| Quick Add | Tanımlanan kuralı hızlıca eklemek için kullanılır. |
| Action | Eklenen kurallar üzerinde işlem yapılmasını sağlar. |
Burada önemli bir ayrım vardır. Ekrandaki açıklamaya göre bu syslog yönlendirme kuralları provision edilen workload’lar ve HVM host’lardan gelen syslog kayıtlarını harici syslog sunucusuna iletmek için kullanılır.
Morpheus appliance’ın kendi işletim sistemi loglarının yönlendirilmesi ise bu alandan yapılmaz. Appliance log forwarding işlemi ayrıca appliance işletim sistemi üzerinde genellikle rsyslog yapılandırması veya appliance CLI üzerinden yapılmalıdır.
Bu ayrım özellikle troubleshooting sırasında önemlidir. Çünkü Morpheus arayüzündeki Syslog Forwarding Rules alanına kural eklemek appliance’ın kendi /var/log/morpheus/ altındaki loglarını otomatik olarak harici syslog sunucusuna göndereceği anlamına gelmez.
7. Appliance Logları ve Yönetilen Sistem Logları Arasındaki Fark
Morpheus logging yapısını doğru anlamak için appliance logları ile yönetilen sistem loglarını ayırmak gerekir.
Yönetilen sistem logları, Morpheus agent kurulu olan VM, host veya workload’lardan gelen loglardır. Bu loglar Morpheus arayüzünde instance, app, host detaylarında veya Monitoring > Logs bölümünde görüntülenebilir.
Appliance logları ise Morpheus’un kendi sistem bileşenlerine ait loglardır. Bunlar genellikle appliance işletim sistemi üzerinde yer alır ve Morpheus’un kendi servislerinin durumunu analiz etmek için kullanılır.
Appliance logları çoğunlukla şu dizinde bulunur:
/var/log/morpheus/
Ayrıca Morpheus arayüzündeki Administration > Health ekranı da appliance sağlığını ve bazı sistem bileşenlerini incelemek için kullanılabilir.
Bu nedenle bir monitoring veya logging problemi analiz edilirken önce sorunun hangi katmanda olduğu belirlenmelidir:
- Problem izlenen bir VM veya workload ile mi ilgili?
- Morpheus agent log göndermiyor mu?
- Appliance’ın kendi servislerinde mi sorun var?
- ElasticSearch veya log saklama katmanında mı problem yaşanıyor?
- Syslog yönlendirme kuralı mı çalışmıyor?
Bu ayrımı yapmak sorun giderme sürecini hızlandırır.
Monitoring Ayarları İçin Önerilen Yaklaşım
HPE Morpheus Enterprise ortamında monitoring yapılandırması yapılırken yalnızca ayarları açıp kapatmak yeterli değildir. Bu ayarların kurumun operasyonel ihtiyaçlarına SLA beklentilerine ve sistem kritiklik seviyelerine göre planlanması gerekir.
Genel olarak aşağıdaki yaklaşım uygulanabilir.
Auto Create Checks Açık Bırakılmalı
Çoğu ortamda Auto Create Checks özelliğinin açık bırakılması önerilir. Böylece yeni oluşturulan sistemler otomatik olarak izleme kapsamına alınır.
Bu ayarın kapalı olması bazı kaynakların izleme dışında kalmasına neden olabilir. Özellikle self-service portal kullanılan yapılarda tenant kullanıcıları yeni sistemler oluşturduğunda bu sistemlerin otomatik olarak monitoring’e dahil edilmesi büyük avantaj sağlar.
Availability Time Frame SLA Süresiyle Uyumlu Olmalı
Availability Time Frame değeri kurumun SLA raporlama periyoduyla uyumlu seçilmelidir.
Aylık SLA raporu hazırlanıyorsa 30 gün mantıklı bir değerdir. Haftalık operasyon raporları hazırlanıyorsa daha kısa süreler tercih edilebilir. Uzun dönemli trend takibi için ise daha geniş zaman aralıkları değerlendirilebilir.
Availability Precision Raporlama İhtiyacına Göre Belirlenmeli
Availability Precision değer raporlarda ne kadar hassasiyet gerektiğine göre belirlenmelidir.
Genel operasyon takibi için 2 veya 3 ondalık basamak yeterlidir. Çok yüksek erişilebilirlik hedefleri bulunan yapılarda daha yüksek hassasiyet kullanılabilir.
Check Interval Sistem Kritikliğine Göre Kademelendirilmeli
Tüm kontrolleri 1 dakikaya çekmek her zaman daha iyi izleme anlamına gelmez. Bu durum hem izleme altyapısında hem de hedef sistemlerde gereksiz yük oluşturabilir.
Daha doğru yaklaşım, sistemleri kritiklik seviyelerine göre sınıflandırmaktır:
| Sistem Tipi | Önerilen Check Interval |
|---|---|
| Kritik üretim servisleri | 1 – 5 dakika |
| Standart üretim sunucuları | 5 dakika |
| Test / geliştirme ortamları | 10 – 15 dakika |
| Düşük öncelikli sistemler | 15 dakika veya üzeri |
Group Yapısı ile Yedeklilik Doğru Modellenmeli
Yedekli çalışan sistemlerde her node’un düşmesi aynı etkiye sahip değildir. Bu nedenle group yapısı kullanılarak minimum başarılı check sayısı doğru belirlenmelidir.
Bu yaklaşım gereksiz kritik alarmları azaltır ve ekiplerin gerçekten müdahale edilmesi gereken durumlara odaklanmasını sağlar.
ServiceNow Eşleştirmesi Kurum Süreçlerine Göre Yapılmalı
Varsayılan severity-impact eşleştirmesi birçok ortam için uygundur. Ancak her kurumun incident önceliklendirme mantığı farklı olabilir. Bu nedenle Info, Warning ve Critical seviyelerinin ServiceNow tarafında hangi impact değerleriyle açılacağı ITSM ekibiyle birlikte değerlendirilmelidir.
Log Seviyesi ve Retention Dengeli Ayarlanmalı
Log seviyesini çok düşük tutmak daha fazla detay sağlar ancak depolama tüketimini artırır. Çok yüksek tutmak ise önemli ayrıntıların kaçmasına neden olabilir. Aynı şekilde log retention süresi de ihtiyaçlara göre belirlenmelidir. Kısa süreli operasyonel analiz için 7 gün yeterli olabilir. Ancak güvenlik denetimi, regülasyon veya uzun süreli kök neden analizi gerekiyorsa merkezi log yönetim platformu kullanılmalıdır.
![[TR] HPE Morpheus Entperise’da Provisioning Yapılandırması (Platform Genelinde Sunucu ve Uygulama Dağıtım Süreçlerini Doğru Yönetmek)](https://kadirkozan.com/wp-content/uploads/2026/05/hpe_morpheus-ikona-150x150.jpg)