Zerto kullanırken en temel ve en kritik yapılardan biri VPG yani Virtual Protection Group’tur. Zerto’nun replikasyon ve felaket kurtarma mantığı büyük ölçüde bu yapı üzerine kuruludur. Bu nedenle VPG’nin ne olduğunu anlamak ve doğru şekilde oluşturmak sağlıklı bir disaster recovery yapısı kurmanın ilk şartlarından biridir.
En basit haliyle VPG korunacak sanal makinelerin bir grup halinde toplanarak aynı koruma politikasıyla yönetilmesini sağlar. Ancak bu tanım tek başına yeterli değildir. Çünkü VPG sadece VM’leri bir araya getiren sıradan bir grup değildir aynı zamanda bu makinelerin birbirleriyle tutarlı şekilde replike edilmesini, aynı recovery mantığıyla yönetilmesini ve gerektiğinde beraber ayağa kaldırılmasını mümkün kılar.
Örneğin bir uygulama ortamında veritabanı sunucusu, uygulama sunucusu ve web sunucusu varsa bunları tek tek korumak yerine aynı VPG içerisinde toplamak çok daha doğru bir yaklaşımdır. Böylece olası bir felaket anında bu sistemler birbirinden kopuk değil aynı zaman çizgisinde ve aynı tutarlılık mantığıyla kurtarılabilir.
Not : VGP hakkında detaylı bilgiye ulaşmak için “Zerto’da VPG (Virtual Protection Groups) Nedir? Neden Kullanılır?” makalemi okuyabilirsiniz.
Bu makalemde Zerto’da VPG oluşturma sürecini baştan sona, anlaşılır ve pratik bir dille ele alacağız.
VPG oluşturmadan önce bilinmesi gerekenler
VPG oluşturmaya geçmeden önce ortamın hazır olduğundan emin olmak gerekir. Çünkü VPG sihirbazı üzerinden ayar yapmak kolay görünse de arka planda bazı temel bileşenler eksikse süreç sorunsuz tamamlanmaz.
Öncelikle korunan site ile hedef site arasında Zerto eşleşmesinin (Pair) yapılmış olması gerekir. Yani protected site ve recovery site birbirini tanıyor olmalıdır.
Bunun yanında her iki tarafta da VRA (Virtual Replication Appliance) bileşenleri düzgün şekilde kurulmuş ve çalışıyor olmalıdır.
Zerto’nun veri akışı bu yapı üzerinden ilerlediği için VRA tarafında problem varsa VPG oluşturmak mümkün olsa bile koruma sağlıklı olmayacaktır.
Ayrıca kaynak taraftaki sanal makinelerin Zerto tarafından görülebiliyor olması hedef tarafta yeterli datastore kapasitesinin bulunması ve kullanılacak ağların önceden planlanmış olması gerekir. Özellikle journal için ayrılacak alan ve recovery sırasında kullanılacak network eşleşmeleri önceden netleştirilirse VPG oluşturma aşaması çok daha sorunsuz ilerler.
Kısacası VPG oluşturma işi sadece “birkaç VM seçip devam etmekten” ibaret değildir. Arkasında storage, network, host, cluster ve replikasyon tasarımının doğru yapılmış olması gerekir.
Zerto arayüzünde VPG oluşturma süreci nasıl başlar?
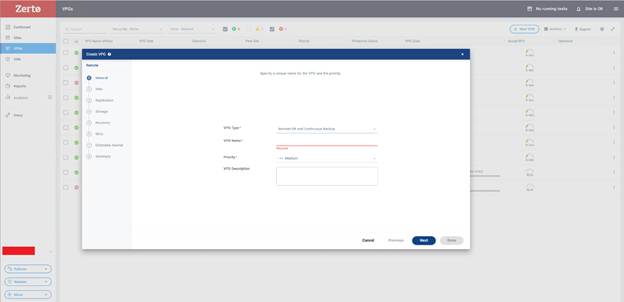
VPG oluşturmak için öncelikle Zerto yönetim arayüzüne giriş yapılır. Ardından sol menüden ya da ilgili bölümden VPGs ekranına geçilir ve burada bulunan New VPG seçeneği kullanılarak yeni bir koruma grubu oluşturulmaya başlanır. Bu işlemle birlikte Zerto’nun sihirbaz yapısındaki yapılandırma ekranı açılır.
1. General bölümünde VPG’nin kimliği tanımlanır
Bundan sonraki aşamalarda sistem senden sırayla genel bilgiler, korunacak VM’ler, replikasyon tercihleri, storage hedefleri, recovery ayarları, network eşleşmeleri ve gerekiyorsa Re-IP bilgilerini ister.
Her adım bir sonrakini etkilediği için burada hızlı davranmak yerine bilinçli ilerlemek çok önemlidir.
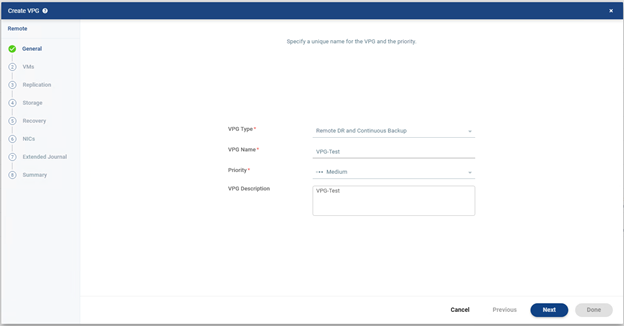
İlk aşamada oluşturulacak VPG için temel bilgiler girilir. Burada genellikle VPG adı, öncelik seviyesi ve açıklama gibi alanlar bulunur.
- VPG Type : Zerto’da bu ekranda görünen VPG Type türleri şunlardır;
- Remote DR and Continuous Backup
Uzak felaket kurtarma ve sürekli yedekleme için kullanılır.
Genelde bir production ortamındaki sanal makineleri başka bir siteye replike etmek ve gerektiğinde oradan ayağa kaldırmak için seçilir.
- Local Continuous Backup
Yerel ortamda sürekli yedekleme amacıyla kullanılır.
DR senaryosundan çok, aynı lokasyon içinde geri dönüş noktaları oluşturmak ve hızlı restore yapmak için tercih edilir.
- Data Mobility and Migration
Veri taşıma ve migration işlemleri için kullanılır.
Örneğin bir workload’u farklı bir cluster’a, site’a ya da ortama taşımak istediğinde bu seçenek uygundur.
Kısaca özetlersek:
DR + replikasyon istiyorsan: Remote DR and Continuous Backup
Aynı lokasyonda sürekli koruma istiyorsan: Local Continuous Backup
Taşıma / geçiş yapacaksan: Data Mobility and Migration
- VPG Name : Buraya oluşturduğun koruma grubunun ismi yazılır. Bu isim gelişigüzel verilmemelidir. Çünkü ileride onlarca VPG olduğunda yönetimi kolaylaştıran en önemli unsurlardan biri doğru isimlendirmedir.
- Priority : Bu alan VPG’nin replikasyon tarafındaki önceliğini belirler. Özellikle yoğun ortamlarda ya da WAN hattının sınırlı olduğu senaryolarda yüksek öncelik verilen VPG’ler daha kritik kabul edilir. Bu yüzden iş açısından önemli olan sistemlerde priority değerinin doğru seçilmesi gerekir.
- Description : Buraya isteğe bağlı olarak açıklama yazılabilir. Büyük ortamlarda bu alan çok faydalı olur. Örneğin “ERP production application servers and database” gibi kısa ama anlamlı bir açıklama ileride ciddi kolaylık sağlar.
Bu aşama basit görünür ancak aslında VPG’nin yönetimsel temelini oluşturur.
2. Hangi sanal makinelerin korunacağı seçilir
Bir sonraki aşamada VPG içine dahil edilecek sanal makineler belirlenir. Bu belki de sihirbazın en kritik bölümlerinden biridir. Çünkü burada yapılan seçim hem recovery mantığını hem de uygulama tutarlılığını doğrudan etkiler.
Zerto’nun en büyük avantajlarından biri ilişkili sistemleri tek bir koruma grubu altında yönetebilmesidir. Bu nedenle birbirine bağımlı çalışan sunucuları aynı VPG altında toplamak en doğru yaklaşımdır.
Örneğin bir uygulama yapısında:
- Veritabanı sunucusu
- Uygulama sunucusu
- Web sunucusu aynı VPG içinde bulunmalıdır.
Çünkü olası bir failover durumunda bu üç makinenin aynı checkpoint mantığıyla toparlanması gerekir. Eğer bunlar farklı VPG’lere dağılırsa birinin recovery noktası diğerinden farklı olabilir ve bu durum uygulama tarafında tutarsızlığa yol açabilir.
Burada dikkat edilmesi gereken önemli nokta şudur:
Aynı VPG içine sadece teknik olarak değil, işlevsel olarak da birbirine bağlı makineler konulmalıdır. Birbiriyle ilgisiz sistemleri aynı VPG’ye almak yönetimi zorlaştırır ve recovery esnasında gereksiz bağımlılıklar yaratır.
Bu ekranda yer alan seçenekler;
- Unprotected VMs
Sol tarafta yer alır. Henüz bu VPG’ye eklenmemiş VM’leri gösterir. Senin örneğinde Zerto-Test isimli sanal makine burada görünüyor.
- Selected VMs
Sağ tarafta yer alır. VPG içine dahil edilmiş VM’ler burada listelenir. Şu an boş olduğu için No Data To Display yazıyor.
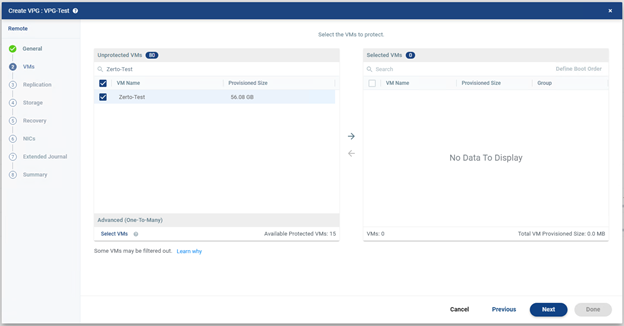
Ortadaki ok butonları ile;
- Sağa ok (→): Solda seçtiğin VM’yi VPG’ye ekler,
- Sola ok (←): Sağ taraftaki seçili VM’yi VPG’den çıkarır,
Bu ekranda yapılması gereken işlem soldaki listeden korumak istediğin VM’yi işaretlenir ve ortadaki sağ oka (→) basılarak VM sağdaki Selected VMs alanına geçişi yapılır. Sonra “Next” ile bir sonraki işleme geçmek için devam edilir.
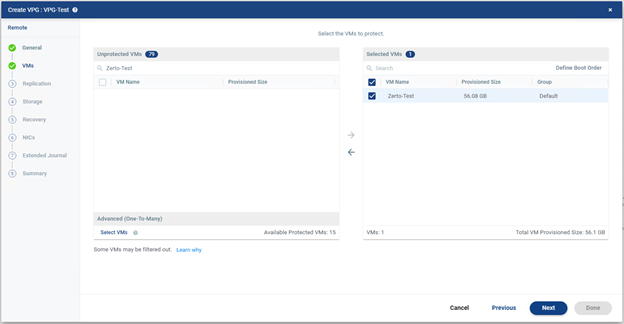
Not :
“Selected VMs” bölümünde yer alan “Define Boot Order” seçeneği ile Failover sırasında VM’lerin açılış sırasını belirlemek için kullanabilirsiniz.
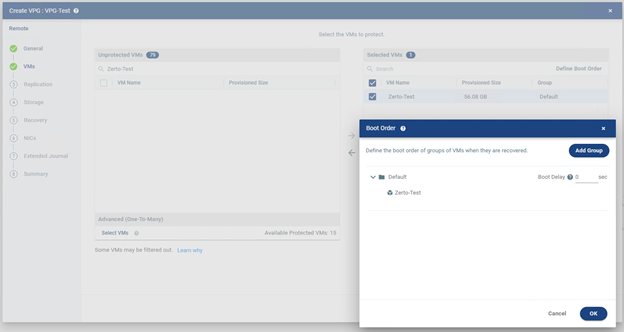
VM’ler seçildikten sonra ihtiyaç varsa bu makinelerin recovery anında hangi sırayla açılacağı tanımlanabilir. İşte bu bölüm boot order ayarıdır.
Bu özellik özellikle çok katmanlı uygulamalarda büyük önem taşır. Çünkü her sunucu aynı anda açıldığında her zaman sağlıklı sonuç alınmaz. Örneğin veritabanı sunucusu hazır olmadan uygulama sunucusunun, uygulama sunucusu hazır olmadan da web sunucusunun açılması çeşitli servis hatalarına neden olabilir.
Doğru bir örnek sıra genelde şu şekilde olur:
- Database sunucusu
- Application sunucusu
- Web sunucusu
Bu sayede servisler birbirini bekleyerek daha kontrollü biçimde ayağa kalkar. Küçük ortamlarda boot order çoğu zaman göz ardı edilir, ancak gerçek failover anlarında ne kadar önemli olduğu net şekilde anlaşılır.
3. Replication ayarları yapılandırılır
Bu aşamada Zerto’nun koruma mantığını belirleyen temel replikasyon ayarları yapılır. Buradaki en dikkat çekici alanlardan biri journal history’dir.
Journal history ne kadar geriye dönük checkpoint saklanacağını belirler. Bu Zerto’nun en güçlü özelliklerinden biridir. Çünkü klasik snapshot mantığından farklı olarak sistem belirli zaman noktalarına dönme esnekliği sunar.
Örneğin:
- 1 saat
- 4 saat
- 8 saat
- 24 saat
- 7 gün gibi seçenekler kullanılabilir.
Bu ne işe yarar?
Diyelim ki bir sistemde bozulma, veri silinmesi, şifrelenme veya mantıksal hata oluştu. Eğer yeterli journal geçmişin varsa sadece en son noktaya değil problemin yaşanmadığı daha eski bir checkpoint’e dönme şansın olur.
Ancak burada önemli bir denge vardır:
Journal süresi arttıkça storage tüketimi de artar. Bu yüzden “olabildiğince yüksek olsun” mantığı her zaman doğru değildir. Ortamın kapasitesi, kritikliği ve RPO/RTO beklentileri birlikte değerlendirilmelidir.
Ayrıca bazı ortamlarda bu bölümde test reminder SLA benzeri takip alanları ya da sıkıştırma ile ilgili ayarlar da bulunabilir. Bunlar sürüme ve kurulum tipine göre değişebilir.
Bu ekranda yer alan seçenekleri tek tek inceleyelim;
- Recovery Site: Burada replikasyonun gönderileceği hedef site seçilir. Yani bu VPG içindeki VM’ler bu uzak site’a replike edilecek.
- Default Recovery Servers: Bu bölümde failover anında VM’lerin varsayılan olarak hangi altyapıda ayağa kalkacağı belirlenir.
Host : Failover sonrası VM’nin çalıştırılacağı ESXi host seçilir. Eğer belirli bir host seçmezseniz bazı ortamlarda cluster veya Zerto uygun host seçimini kendi yapabilir. Ama kontrollü bir yapı istiyorsan burada doğru host’u seçmek önemlidir.
Datastore : Recovery site tarafında replika disklerin veya recovery disklerinin tutulacağı datastore seçilir. Bu alan çok kritiktir çünkü hedef datastore yeterli kapasiteye sahip olmalı, erişilebilir olmalı, Zerto ve hedef host tarafından görülebilmelidir.
- SLA : Bu bölüm VPG’nin koruma politikasını belirler.
Journal History : Ekranda 1 Days görünüyor. Bu Zerto’nun journal üzerinde 1 günlük geri dönüş noktası tutacağı anlamına gelir. Yani teoride son 1 gün içindeki bir noktaya dönme şansın olur. Örneğin bir dosya bozulduysa veya sistemde mantıksal bir problem olduysa, sadece son replika durumuna değil, journal içindeki önceki zamana da dönebilirsin.
Dikkat edilmesi gereken konu Journal süresi arttıkça storage tüketimi de artar.
Target RPO Alert: Ekranda 5 Minutes seçilmiş. Bu hedef RPO değerinin 5 dakika olduğunu gösterir. Yani Zerto korunan VM’lerin en fazla 5 dakikalık veri kaybı sınırında kalmasını hedefler. Bu süre aşılırsa alarm üretebilir.
Test Reminder: Ekranda 6 Months görünüyor. Bu ayar DR testlerinin unutulmaması için hatırlatma üretir. Yani yaklaşık 6 ayda bir test yapman gerektiğini hatırlatır.
- Enable WAN Traffic Compression: Bu kutu işaretli olmalıdır. Bu özellik siteler arası veri aktarımında WAN trafiğini sıkıştırır. Böylelikle bant genişliği kullanımını azaltabilir özellikle uzak lokasyonlarda faydalı olabilir.
Ama çok güçlü hatlarda veya özel performans senaryolarında ortamına göre değerlendirmek gerekir. Genelde açık bırakılması mantıklıdır.
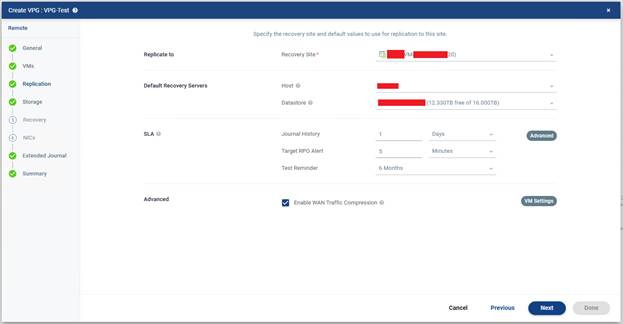
Not :
SLA dizininde bulunan “Advanced” butonu daha detaylı SLA yada replikasyon ayarlarına girmeni sağlar. Buradan daha ince politika ayarları yapılabilir.
VPG içindeki VM’ler için özel ayar yapmanı sağlar. Örneğin bazı VM’ler için farklı recovery ayarları veya özel yapılandırmalar tanımlanabilir.
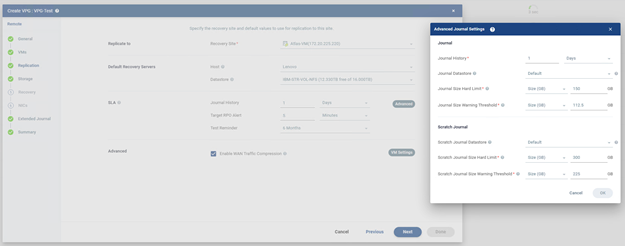
Burada VPG’nin journal alanı ve scratch journal alanı için daha detaylı kapasite ve uyarı ayarları yapılır. Kısacası bu bölümdür geri dönüş noktalarının tutulduğu journal alanının ne kadar büyüyebileceğini ve ne zaman uyarı vereceğini belirler.
Aşağıda alanları tek tek açıklayayım:
- Journal bölümü Journal History : Burada 1 Days seçilmiş. Bu Zerto’nun journal üzerinde 1 günlük geçmiş tutmaya çalışacağı anlamına gelir. Yani sistem mümkün olduğu sürece son 1 gün içindeki geri dönüş noktalarını saklar. Bu sayede bir sorun olduğunda sadece son replika anına değil o 1 günlük pencere içindeki önceki bir zamana dönme şansın olur.
Ancak burada önemli nokta şudur: Journal history değeri tek başına yeterli değildir. Altta tanımlanan journal kapasitesi de bu süreyi desteklemelidir. Eğer yeterli alan yoksa Zerto istenen süreyi tam tutamayabilir.
- Journal Datastore : Burada Default seçili. Bu alan journal verisinin hangi datastore üzerinde tutulacağını belirler.
Default seçildiğinde sistem VPG için varsayılan journal datastore ayarını kullanır. Eğer ortamında journal’ı özel bir datastore üzerinde tutmak istiyorsan buradan manuel seçim yapabilirsin. Bu datastore için dikkat edilmesi gerekenler yeterli boş alan olmalı, erişilebilir olmalı, performansı yeterli olmalı ve recovery tarafında düzgün eşlenmiş olmalıdır.
Journal Size Hard Limit: Burada 150 GB tanımlanmış. Bu journal alanı için belirlenen kesin üst sınırdır. Yani journal büyüyebilir, ama 150 GB’ı aşamaz. Bu sınır, kontrolsüz storage tüketimini önlemek için kullanılır.
Şunu bilmek önemli: Eğer journal history 1 gün olarak ayarlanmış olsa bile değişim oranı yüksek bir VM’de 150 GB yetmezse sistem tam 1 günlük geçmişi koruyamayabilir. Çünkü kapasite sınırı journal geçmiş süresini fiilen kısıtlayabilir.
Journal Size Warning Threshold: Burada 112.5 GB görünüyor. Bu warning yani uyarı eşiğidir. Journal boyutu bu seviyeye ulaştığında sistem henüz hard limit’e gelmeden önce uyarı üretir. Böylece storage dolmadan önce müdahale etme şansın olur.
Bu ekran özelinde mantık şu:
- 112.5 GB → uyarı seviyesi
- 150 GB → maksimum sınır
Yani journal alanı büyürken önce uyarı verilir, sonra limit’e dayanır.
Scratch Journal bölümü:
Scratch journal journal işlemleri sırasında kullanılan ek çalışma alanı gibi düşünülebilir. Özellikle yoğun değişim, senkronizasyon veya özel durumlarda devreye giren yardımcı alandır. Bunu Zerto’nun journal işlemlerini daha güvenli ve kontrollü yürütmesi için kullandığı ek disk alanı olarak düşünebilirsin.
- Scratch Journal Datastore: Burada da Default seçili. Yani scratch journal için de varsayılan datastore kullanılacak. İstersen bunu farklı bir datastore’a yönlendirebilirsin. Özellikle performans veya kapasiteyi ayrı yönetmek isteyen ortamlarda bu tercih edilebilir.
- Scratch Journal Size Hard Limit: Burada 300 GB tanımlı. Bu scratch journal alanının ulaşabileceği maksimum boyuttur. Journal hard limit’ten daha yüksek verilmiş olması normaldir. Çünkü scratch alanı bazı durumlarda daha geniş çalışma alanı ihtiyacı doğurabilir.
- Scratch Journal Size Warning Threshold: Burada 225 GB yazıyor. Bu da scratch journal için uyarı eşiğidir.
Mantık yine aynıdır.
- 225 GB → uyarı
- 300 GB → kesin üst limit
4. Storage hedefleri seçilir.
Storage bölümü kaynak taraftan gelen verilerin hedef tarafta nereye yazılacağını belirlediğin aşamadır. Bu kısım yanlış planlanırsa ileride performans, kapasite ve erişim sorunları yaşanabilir.
Burada genellikle iki temel alan öne çıkar:
- Recovery datastore
- Journal datastore
Recovery datastore: Failover sonrasında VM disklerinin kullanılacağı esas depolama alanıdır.
Journal datastore: Checkpoint geçmişinin saklandığı alandır. Bu alan, performans açısından oldukça önemlidir. Çünkü journal yapısı sürekli çalışan ve değişimi işleyen bir mekanizmadır.
Yanlış storage seçimi şu tip sorunlara neden olabilir:
- Journal history çok düşük görünür
- Hedef tarafta alan yetersiz kalır
- Recovery diskleri erişilemez hale gelir
- Replikasyon performansı düşer
Bu yüzden storage seçimi yapılırken sadece boş alan miktarına değil performans ve erişim yapısına da dikkat edilmelidir.
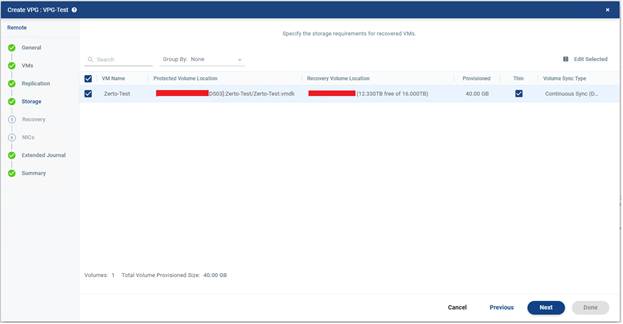
Not :
“Thin” kutucuğu işaretliyse disk hedef tarafta “thin provisioned” olarak oluşturulur.
5) Recovery ayarları tanımlanır.
Bu aşamada failover gerçekleştiğinde VM’lerin hedef tarafta nasıl oluşturulacağı belirlenir. Yani recovery site üzerinde hangi cluster, hangi host, hangi resource pool veya hangi klasör yapısının kullanılacağı bu bölümde seçilir. Buradaki mantık şudur replikasyon yapmak ayrı bir şeydir failover anında sistemi gerçekten çalıştırabilecek doğru hedefi hazırlamak ayrı bir şeydir.
Örneğin hedef tarafta yanlış host seçilmişse datastore görünürlüğü olmayan bir cluster belirlenmişse ya da uygun resource pool kullanılmamışsa, VPG teknik olarak var olur ama recovery anında sorun yaşanır.
Bu nedenle recovery ayarları yapılırken sadece mevcut duruma değil gerçek bir felaket anında sistemin nasıl ayağa kaldırılacağına göre düşünmek gerekir.
Bu ekranda yer alan seçenekler;
Default Recovery Settings : VM’nin ağ ayarlarını belirlenir.
- Failover/Move Network : Burada gerçek failover veya move işlemi sırasında VM’nin bağlanacağı hedef ağ seçilir. Bu şu anlama gelir gerçek bir felaket anında ya da planned move yaptığında VM recovery site tarafında açıldığında bu port group / network’e bağlanacak. Bu alan çok önemlidir. Çünkü yanlış network seçilirse VM açılır ama iletişim kuramaz, IP erişimi olmaz, uygulama çalışsa bile kullanıcılar ulaşamaz ve VLAN hataları oluşabilir.
- Failover Test Network : Bu alan test failover sırasında kullanılacak ağı belirler. Normalde test failover için çoğu ortamda izole bir network seçilir. Çünkü test sırasında production ile çakışma olmaması istenir. Özellikle aynı IP’leri kullanan makinelerde bu çok kritiktir. Yani iyi uygulama genelde şöyledir:
Failover/Move Network → gerçek çalışma ağı
Failover Test Network → izole test ağı
Eğer test network ile gerçek network aynı seçilirse test sırasında dikkatli olunmalıdır. Ortam tasarımına göre IP çakışması veya erişim karmaşası olabilir.
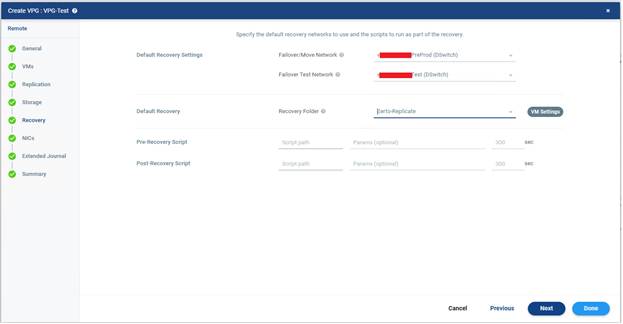
Recovery Folder : Burada recovery site üzerinde VM’nin hangi klasör altında oluşturulacağı belirlenir. Yani failover sonrası ayağa kalkan VM’lerin vCenter tarafında bu klasör altında görünecek. Bu alanın faydası şudur; recovery VM’leri düzenli tutulur, production VM’lerle karışmaz, yönetim kolaylaşır ve çok sayıda VPG varsa takip daha rahat olur.
VM Settings: Bu buton VPG içindeki VM’ler için varsayılan recovery ayarlarının dışında özel tanım yapmanı sağlar.
Örneğin bazı VM’lerde farklı network, farklı recovery folder, özel boot sırası, özel recovery davranışı tanımlamak için kullanılabilir. Tek VM’li yapılarda çok gerekmeyebilir ama çoklu VM içeren VPG’lerde oldukça faydalıdır.
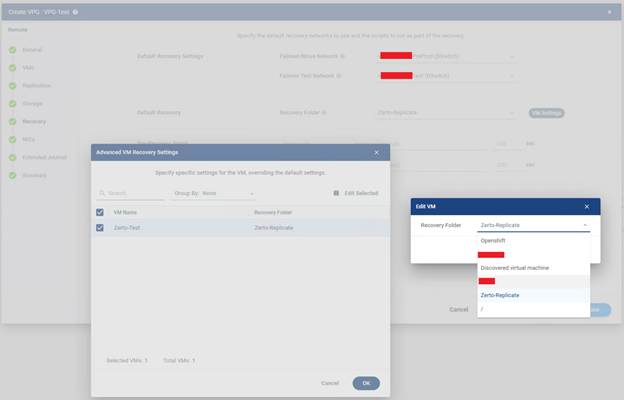
Pre-Recovery Script: Bu alan recovery işlemi başlamadan önce çalıştırılacak script’i tanımlamak içindir. Burada genelde şu bilgiler girilir:
- Script path
- Params (optional)
- timeout süresi
Bu script ne işe yarar? Örneğin bağımlı servisleri hazırlamak, bir kontrol mekanizması çalıştırmak, ağ veya uygulama ön hazırlığı yapmak, bazı otomasyon tetiklemeleri başlatmak için Recovery başlamadan hemen önce çalışır.
Post-Recovery Script : Bu alan ise recovery işlemi tamamlandıktan sonra çalıştırılacak script içindir. Yine burada:
- script path
- opsiyonel parametre
- timeout tanımlanır.
Bu scriptler şu amaçlarla kullanılabilir servis kontrolü yapmak, uygulama ayağa kalktı mı doğrulamak, DNS update tetiklemek, monitoring agent başlatmak ve log toplama veya bildirim göndermek için.
6) Network eşleşmeleri yapılır
Felaket kurtarma planlarında en çok hata yapılan alanlardan biri network tasarımıdır. Zerto’daki network bölümü de bu yüzden son derece önemlidir.
Bu aşama Zerto’daki NICs adımıdır. Burada VM’nin ağ kartı bilgilerinin recovery tarafında nasıl eşleneceği belirlenir. Yani temel olarak şu soruya cevap verir:
“Korunan VM failover olduğunda hangi ağa bağlanacak ve istersem IP ayarı ne olacak?”
Burada genellikle iki farklı ağ mantığı tanımlanır:
- Failover network
- Test network
Failover Network : Gerçek bir felaket anında VM’lerin bağlanacağı üretimsel DR ağıdır.
Test Network: Failover testleri sırasında kullanılacak, tercihen izole edilmiş test ağıdır.
Bu ayrım çok önemlidir. Çünkü test sırasında VM’lerin yanlışlıkla canlı üretim ağına çıkması ciddi sorunlara yol açabilir. IP çakışmaları, DNS karışıklıkları ya da istemeden canlı servis etkisi gibi problemler yaşanabilir.
Bu yüzden network mapping yapılırken şu mantık net olmalıdır. Kaynak üretim ağı hangi hedef ağa düşecek? Test anında bu VM’ler hangi izole ağa bağlanacak?
Sağlıklı bir DR tasarımında test network’ü mutlaka kontrollü ve izole bir yapı olmalıdır.
Özellikle DR senaryolarında en kritik bölümlerden biridir. Çünkü VM recovery tarafında doğru storage’a inse bile yanlış ağa bağlanırsa hizmet veremez.
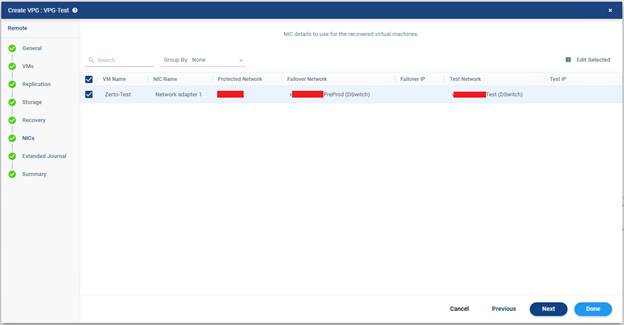
Bu ekranda yer alan sütunlar;
- VM Name : Burada ilgili sanal makinenin adı görünür.
- NIC Name : Bu sütun VM üzerindeki ağ kartını gösterir. Eğer VM’de birden fazla NIC olsaydı burada ayrı ayrı listelenirdi. Örneğin: Network adapter 1, Network adapter 2, Network adapter 3 Her biri için farklı ağ eşlemesi yapılabilirdi.
- Protected Network : Bu alan VM’nin kaynak tarafta şu anda bağlı olduğu ağı gösterir. Yani VM production tarafında şu anda bu network üzerinde çalışıyor.
- Failover Network : Bu alan gerçek failover veya move sırasında VM’nin recovery site tarafında bağlanacağı ağı gösterir. Yani gerçek DR anında bu VM recovery ortamında bu hedef ağa bağlanacak. Bu seçim çok önemlidir. Çünkü yanlış network seçilirse VM açılır ama erişilemez, uygulama servis veremez, kullanıcılar bağlanamaz, VLAN veya routing sorunları oluşabilir.
- Failover IP: Bu sütun gerçek failover sırasında uygulanacak IP yapılandırmasını gösterir. Buranın boş olması genelde şu anlama gelir IP reconfiguration tanımlanmamış olabilir. VM açıldığında mevcut işletim sistemi ağ ayarıyla devam edebilir ya da DHCP / manuel OS konfigürasyonuna bırakılmış olabilir.
Bazı ortamlarda Zerto ile failover sırasında IP değişikliği yapılır. Özellikle production ve DR site farklı subnet kullanıyorsa bu alan önemli hale gelir.
- Test Network: Bu alan test failover sırasında VM’nin bağlanacağı ağı gösterir. Burada farklı networklerin seçimi çok doğru bir yaklaşımdır çünkü test failover için ayrı veya izole bir ağ kullanmak genelde en iyi yöntemdir. Böylece production ile IP çakışması önlenir, test ortamı kontrollü olur, sistemler güvenli şekilde doğrulanır.
- Test IP : Bu alan test failover sırasında kullanılacak IP yapılandırmasını gösterir. Eğer test ağı farklı subnet’teyse ve VM’nin ayağa kalkınca erişilebilir olması isteniyorsa burada IP re-IP kuralları planlanabilir.
Bu ekranda gerekirse Re-IP tanımlanabilir. Kaynak ve hedef lokasyondaki ağ yapısı aynı değilse failover sonrası VM’lerin IP adreslerinin değiştirilmesi gerekir. İşte bu noktada Re-IP ayarı devreye girer. Örneğin kaynak ortamda sunucu 10.10.10.20 IP’siyle çalışıyorsa, DR tarafında bu sistemin 192.168.100.111 olarak ayağa kalkması istenebilir. Böyle bir durumda Zerto üzerinde ilgili VM için Re-IP ayarı tanımlanmalıdır.
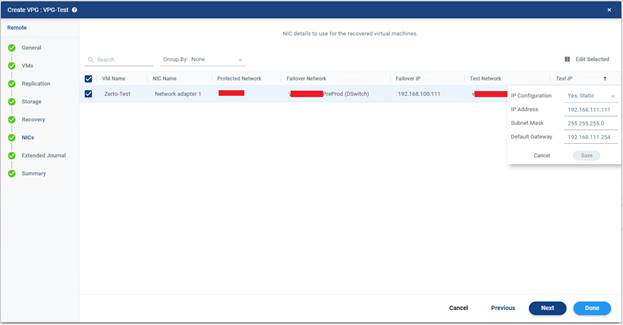
Bu ayarlar genelde şu bilgileri içerir:
- Yeni IP adresi
- Subnet mask
- Gateway
- DNS bilgileri
Re-IP konusu kâğıt üzerinde basit görünür ama pratikte oldukça kritiktir. Çünkü failover sonrası sistem açılmış olsa bile doğru ağa ve doğru IP yapısına oturmuyorsa uygulama tarafı çalışmayabilir. Özellikle farklı subnet’ler ve çok katmanlı uygulamalar söz konusu olduğunda bu alan dikkatle ele alınmalıdır.
7) External Journal yapılandırılır.
Bu aşama standart journal’dan farklı olarak korunan VM’lerin daha uzun süreli saklanması için ek kopya tutma mantığını yönetir. Normal journal kısa ve sürekli geri dönüş noktaları sağlar. Extended Journal ise daha uzun vadeli saklama ihtiyacı için kullanılır. Yani mantık şu şekildedir
“Son birkaç saat veya gün değil, daha uzun periyotlarla saklanan ek geri dönüş kopyaları olsun.”
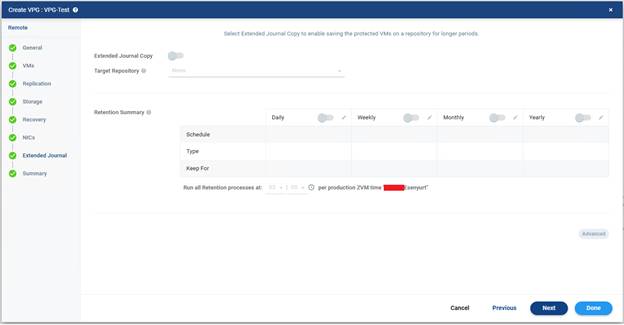
Bu ekranda yer alan seçenekler;
Extended Journal Copy : Varsayılan ayarlarda kapalı olarak gelmektedir ve ek olarak ”External Journal Copy lisansı” gerektirir.
Bu seçenek açıldığında Zerto korunan VM’lerin extended journal kopyalarını belirlenen repository üzerinde tutmaya başlar. Yani sadece standart journal ile yetinmez, daha uzun periyotlu saklama politikası da uygular.
Bu özellik açık olduğunda:
- Target Repository seçmen gerekir,
- Retention politikaları aktif hale gelir,
Günlük, haftalık, aylık, yıllık saklama kuralları tanımlanabilir
Target Repository : Şu anda None görünüyor. Çünkü Extended Journal Copy aktif değildir. Bu alan extended journal verilerinin hangi repository üzerinde tutulacağını belirler. Yani uzun süreli saklanacak kopyaların yazılacağı hedef alan burasıdır.
Burada seçilecek repository için dikkat edilmesi gerekenler;
- yeterli kapasite olmalı,
- uzun süreli saklamaya uygun olmalı,
- performans ve erişim yapısı uygun olmalı,
- retention planına göre büyüme hesaplanmalıdır.
Retention Summary : Bu bölüm extended journal açık olduğunda hangi periyotlarda kopya tutulacağını belirlediğin alandır. Burada dört ana saklama kategorisi var:
- Daily : Günlük saklama politikasıdır. Açılırsa belirli bir plana göre her gün bir extended copy alınır ve belirlediğin süre kadar saklanır. Örnek mantık Her gün 1 kopya al 14 gün sakladır.
- Weekly: Haftalık saklama politikasıdır. Belirli bir gün alınan haftalık kopyalar daha uzun süre tutulabilir. Örnek Her pazar 1 kopya al, 8 hafta sakladır.
- Monthly : Aylık saklama politikasıdır. Ay bazlı uzun süreli saklama için kullanılır. Örnek Her ayın ilk günü 1 kopya al ve 12 ay sakladır.
- Yearly : Yıllık saklama politikasıdır. Daha çok uzun süreli arşiv veya denetim ihtiyacı olan yapılarda kullanılır. Örnek Yılda 1 kez kopya al ve 3 yıl veya 5 yıl sakla şeklindedir.
“Run all Retention processes at” Bu alan retention işlemlerinin hangi saatte çalışacağını gösterir. Varsayılan ayarlarda 03:00 görünüyor. Bu şu anlama gelir Retention işlemleri production ZVM zamanına göre gece 03:00’te çalışacak şekilde planlanmış. Alt tarafta görünen ifade de bunu destekliyor per production ZVM time “____Esenyurt” yani zaman referansı production tarafındaki ZVM saatidir. Bu saat genelde yoğunluğun düşük olduğu zamanlara ayarlanır. Çünkü retention işlemleri storage ve sistem kaynaklarını etkileyebilir.
Sağ altta görünen “Advanced” butonu extended journal için daha detaylı ayarların yapılabildiği bölümdür. Burada daha gelişmiş retention davranışları veya repository kullanım detayları yönetilebilir. Şu an pasif görünmesinin nedeni yine Extended Journal Copy’nin kapalı olmasıdır.
8) Son özet kontrol edilir.
Tüm ayarlar tamamlandıktan sonra Zerto genellikle bir özet ekranı sunar. Bu ekranda şimdiye kadar yapılan tüm seçimler toplu şekilde görüntülenir.
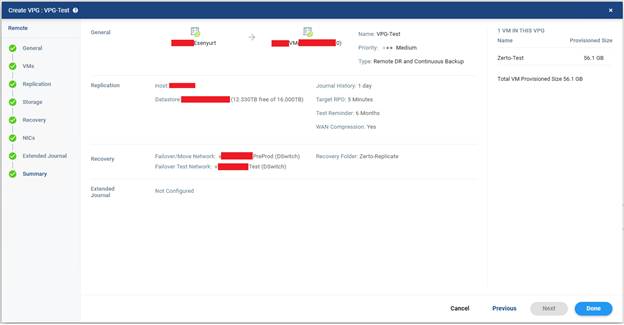
Bu noktada acele edilmemelidir. Şunlar mutlaka tekrar gözden geçirilmelidir:
- VPG adı doğru mu?
- Doğru VM’ler seçilmiş mi?
- Journal süresi uygun mu?
- Recovery datastore doğru mu?
- Journal datastore yeterli mi?
- Hedef host ve cluster doğru mu?
- Network mapping doğru yapılmış mı?
- Test network izole mi?
- Re-IP gerekiyorsa eksiksiz mi?
- Boot order mantıklı mı?
Bu son kontrol ileride oluşabilecek birçok sorunu daha VPG oluşmadan engeller. Her şey doğruysa “Done” butonuyla işlem tamamlanır.

VPG oluşturulduktan sonra iş bitmiş sayılmaz. Asıl süreç bundan sonra başlar. Çünkü Zerto seçilen VM’lerin ilk kopyasını hedef tarafa göndermeye başlar. Bu aşama “initial sync” olarak adlandırılır.
İlk senkronizasyon tamamlanana kadar şu bilgiler takip edilmelidir:
- VPG status
- Sync progress
- RPO değeri
- Journal durumu
- Oluşan alarm ve görevler
Buradaki amaç VPG’nin gerçekten sağlıklı biçimde koruma altına girip girmediğini doğrulamaktır. Bazen VPG başarıyla oluşturulur ama storage, network veya erişim problemleri nedeniyle senkronizasyon sırasında hata oluşabilir. Bu yüzden ilk sync süreci dikkatle izlenmelidir.